50+ million requests in 7 days on json-schema.org
I grant you, 7 days isn't an ideal length of time to do an analysis over, but this is what we have for now. Previously, we had basic website analytics, but that only tells a fraction of the story. We run the website on GitHub pages with Cloudflare in front, which provides 7 days of analytics, critically, including direct access traffic.
The JSON Schema website hosts the official meta-schemas. If you're not sure what that means, meta-schemas are JSON Schemas for JSON Schema. Why is this interesting? Well, we host all historical versions of the meta-schema, not just the most recent. And while we don't expect code to be making requests on a regular basis to download the meta-schemas, the number of requests strongly suggests that they do.
Why now? In addition to providing meta-schemas at versioned URLs, the web site has, and continues to, provide the latest meta-schema at /schema. We currently advise people not to be accessing this! We put in a delayed redirect with a message warning people to avoid it, but realistically, we expect most access will be via code and not in a browser. (This means things are likely broken. More on that later.)
Maybe now we can remove hosting that URL? For reasons out of the scope of this article, using it really isn't a great idea, and will probably produce results you don't expect. As mentioned, web analytics won't tell us what's happening outside of a browser, so we needed something else… We were already using Cloudflare, so decided to submit for the open source free pro tier plan… while we wait, the cost isn't huge, so I decided we should look at the data now.
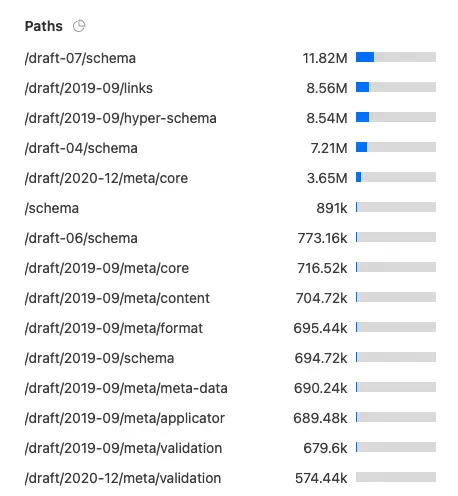
The data in this article is a seven-day snapshot taken at 2023-07-21. (At the end of the article, I'll share an image from this snapshot, and one from 2023-07-31 for comparison.)
Caveat 1: Clients should not be making requests to meta-schemas as part of their production code. It may be appropriate as part of a CI/CD system, but this is also unlikely. Instead, clients should store a local cached copy. Any noticeable number of requests strongly suggests little or no caching.
Caveat 2: The traffic analytics data is based on a sample of the total traffic. Each stat uses a different percentage. Anywhere from 0.16%, to 16.67%. I guess there's a lot of numbers to crunch and logs to keep to do a true analysis. You can ask for logs to be piped to a third party… but you need the enterprise plan. Regardless, the insights are still pretty interesting.
Caveat 3: The "top" of each category of data is limited to 15 items in the UI. I think we could use their API to access additional data, but that's something I couldn't figure out in 5 minutes, so let's use what we have today.
Oh yes, and we are limited to the last SEVEN days worth of data.
What are we sharing here?
It's best if we start with some splashy numbers, then go into what is exactly being accessed and why that's interesting, and finally just some interesting discoveries.
The big numbers
51.92 million requests
211.47GB of data transfer
1.05 million page views
1.01 million visits
All the meta-schemas!
About 51 million of those requests are made from something that doesn't declare a browser, client, or bot name. We see Chrome and Firefox take the top spots, and lower down we see CURL and various indexing bots.
In terms of what paths are accessed, and therefore what meta-schemas, I found the results interesting and insightful.
The top result, at 11.82 million, is /draft-07/schema. This suggests that draft-07 JSON Schema is the most popular passed to misbehaving implementations. (Most well behaved implementations won't go download the meta-schemas, because they already have it! This includes the most popular implementations!)
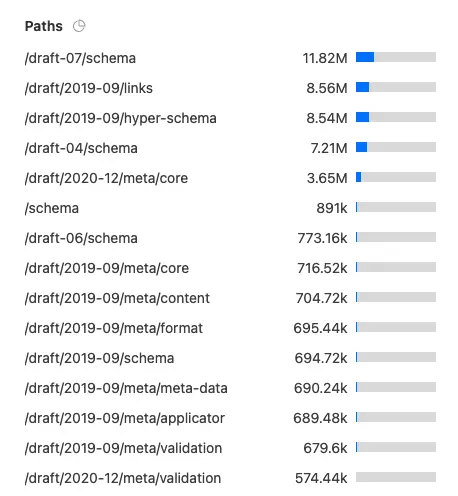
Draft-04 doesn't appear till number 4 in the list. Ranks number 2 and 3 are taken by Draft 2019-09, but not as we might expect… the files there, links and hyper-schema are for Hyper Schema, as opposed to the primary validation use case of JSON Schema.
Someone's accessing Hyper Schema?
Remember, we previously published JSON Hyper Schema in addition to our core offering. Hyper Schema is a hypermedia specification. Specifically, in relation to APIs, Hypermedia as the engine of application state (HATEOAS). (For those interested, further reading: Richardson Maturity Model). We decided to pause JSON Hyper Schema, as we didn't have the resources to champion progressing the specification, around the same time as wrapping up draft 2020-12. (We can ascribe the difference between hyper-schema and links to the sample used. It's reasonable to assume both were accessed sequentially.)
Where are these requests for Hyper Schema meta-schemas coming from? While the physical location is uninteresting, we can look at the user agent provided. The top two, which covers 7.5 million requests, doesn't really help… python-requests. At most, we can see that version 2.27 and 2.28 are roughly in equal use. After that, we jump down to 635k requests, from something identifying as neptune-client. Curiosity piqued!
They call it an "Experiment tracking tool and model registry". This is to do with Machine Learning (ML) Ops (MLOps), built for data scientists and ML engineers. I know very little about ML, so I asked my colleague to share his take on the Neptune.ai service, who knows vastly more about this space…
"Piece of software that, when you tweak something about a machine learning model, let's you run some calculations that tell you how your changes affect how good the model is" - Julian Berman
Well, that's dumbed down enough for me! Thanks Julian!
I guess we should reach out to them to find out about their use case for Hyper Schema!
OK, so who's still accessing /schema?
Accessing the latest meta-schema published using this unversioned URI is not advised. We started making people aware of this about four years ago, and you'll see a message with your redirection if using a browser.
The vast majority of requests to this have no referring source, so that's not very helpful. Turning to user agent, we see the vast majority of requests have a user agent of "". sigh. Yup! blank! This is poor form, and I had a suspicion about what might be causing this.
When you look at the adjacent data, seeing over half of the remaining top 15 user agents, it's pretty clear that most of these requests are coming from IDEs and code editors. We see InteliJ IDEA, WebStorm, and multiple versions of each. But, what we don't see is VSCode.
Sure enough, VSCode, as far as we can tell, doesn't provide a user agent. At least, when making requests related to JSON Schema. While we love VSCode and the baked-in support for JSON Schema, there are a number of things we wish were a little better, and this is one of them.
Visual Studio provides a user agent (and we'll get to that analysis later), but given Visual Studio Code does not, we can't differentiate between requests it is making, and any others which aren't providing a user agent. (We generally see a user agent is given.)
It's important to note here that, due to the limitations of hosting the site on GitHub, the redirect used for /schema is an HTML based header redirect as opposed to using a HTTP 302 status code like you might expect. This means that realistically, it's unlikely any code making these requests is actually getting what they want. (The redirection technique is almost exclusivly followed by browsers, and not developer tools, such as CURL, as it is non-standard). Sure enough, if we try this in Visual Studio Code, we see an "Unable to parse content" error. It expects JSON in the response, but the website does not oblige.
Who is accessing draft-04?
The total number of requests to the draft-04 meta-schema is 7.21 million in the last 7 days.
The physical locations showed one surprise, with Peru taking the lead over the UK and Russia. Next the USA with 5.73 million of those 7.21 million requests.
This time, the user agent data is much more useful. We don't see the empty agent string till slot number 10, accounting for only 78k requests. At the top we see Java! I'm making an educated guess here, and saying this is related to the Java implementation by Francis Galiegue. They were one of the early core team members of JSON Schema, and created a Java implementation, which hasn't upgraded support since draft-04.
From this, we can speculate that many Java services in production using JSON Schema, on AWS, don't have a reason to move away from obsolete implementations of JSON Schema. Maybe they are using a more modern version of JSON Schema itself, and the implementation is handling them incorrectly… but without testing, I'm just making educated guesses at this point.
With Java taking the lions share, 4.11 million, we come next to Mojolicious (a Perl framework), followed by Visual Studio, with 526k. Now that's much more interesting. I also note here, that Visual Studio provides a much more helpful user agent string. Look:
Visual Studio/17.6 (JSON Editor; ASP.NET and Web Tools/17.6.326.62524)
If we account for multiple versions of Visual Studio, we are easily going over 1 million here. They take 8 of the top 15 spots. We already have some lines of communication open with people working on Visual Studio. The same cannot be said for Visual Studio Code. I'm hopeful we can correct that at some point.
Latest three JSON Schema versions?
Let's look at accessing paths with draft-07, 2019-09, and 2020-12.
For draft-07, the path /draft-07/schema was accessed 11.66 million times. The next largest, at 1.8k, is the release notes… as in a HTML file on the website (oh, look, there's a website there too!).
For 2019-09, we see 20.87 million requests. Why the jump? Both links and hyper-schema received over 8 million requests each. As mentioned previously, it's really hard to attribute those requests, but let's see what happens when we exclude them. Now we see 4.05 million… not bad! Although, we have to consider, with 2019-09 we broke up the meta-schema into multiple files, specifically the individual vocabularies. We see just above 500k requests for each of the vocabularies, with slightly more for the general purposes meta-schema, and core.
The user agents for 2019-09, with hyper-schema URLs filtered out, are predominantly Java.
What do we expect to see for 2020-12 then? I was curious too.
We see 7.42 million, and none of those are related to Hyper Schema.
Of that, 1.53 million to .../meta/core, and in the next place, the validation vocabulary meta-schema, with only 577.84k. If this is accurate, it's a little concerning. We would expect /draft/2020-12/schema to be the top path accessed, but it doesn't appear till position 8, with 472.46k.
The traffic pattern is very spikey, with a repeating time based pattern. It's probably some cron job running. If we exclude the top IP address, we lose all the spikes, strongly suggesting this bursting traffic is coming from some Amazon controlled AWS servers.
We'll reach out to AWS and see if we can get any more specific details. It's likely not a DoS attack, but it's a signal of something going wrong.
ASN, OSI, what?
The top two ASN sources are Amazon controlled, totalling just over 39 million requests.
For those of you who aren't network engineers, ASN is an Autonomous System Number, used for routing of packets over the internet, making sure they take the likely fastest route. If you cast your mind back to when you learnt about the OSI model (yeah, I don't remember much of that either), AKA the Open Systems Interconnection model, these ASNs are used as part of the transport layer.
Point is, we can tell without needing to look up IP address owners, that almost 80% of our traffic is coming from AWS!
Country
Given how much traffic is coming from AWS, it's not a surprise that about 43 million of those requests are coming from the US and Ireland. After those, Finland, India, and Netherlands make up the 1 mil club. Following on, Germany and Russia, and then several countries from Asia, all above 200k.
Source
A staggering 51.12 million of those 51.92 million requests, are not declaring a reference. The following top three are json-schema.org, Google, and then, very interestingly, localhost!
Weirdly, 1.54k requests declare a referrer of some defunct Uber settlement, just above Duck Duck Go.
What does this all mean?
Access of meta-schemas is unlikely to correlate with usage percentages, but it is at least an indicator of use to an extent. Looking at this data has meant we are reaching out to AWS to see if we can get any details. It has prompted us to reach out to IDE makers, although doing so was already on our list. We have extended our known platform users. It's nice when people use a proper agent string.
Given we only have access to a 7 day history, there's not much we can tell over a longer time. While traditional analytics are useful, and we do use them, they can't tell us about accessing JSON files directly.
While some of these numbers are interesting to see, I'm yet to be convinced that they provide much utility today.
Here's the side by side traffic for paths from 2023-07-21 and 2023-07-31.
Got any thoughts, comments, feedback on this article? Got any ideas why we are seeing this data? Have some ideas for futher research or analysis? Please, let's discuss this further: https://github.com/orgs/json-schema-org/discussions/480
Photo by Isaac Smith on Unsplash